Generative AI. Đây là thuật ngữ mới nhất trong lĩnh vực AI. Tất cả đều đang nói về nó và nó càng ngày càng ấn tượng hơn. Theo từng ngày trôi qua, khả năng của các mô hình AI trong việc tạo ra nội dung chất lượng cao và thực tế tiếp tục ấn tượng. Ví dụ, chúng ta đã thấy các mô hình AI có thể tạo ra hình ảnh 2D chân dung phức tạp từ các mô tả dòng văn bản cơ bản và đây chỉ là góc nhìn của tảng băng. Khi xu hướng của Generative AI tiếp tục tăng tốc, chúng ta đang chứng kiến những kết quả ấn tượng hơn nữa, ví dụ như các mô hình AI có thể tạo ra video, văn bản và thậm chí cả nhạc với tính thực tế đáng kinh ngạc.
Một trong những tiến bộ lớn trong lĩnh vực này là sự phát triển của các mô hình phân tán, cho phép các mô hình AI sản xuất đầu ra thực tế trước đó bị coi là khó. Chúng ta không thể quên việc phát triển các tập dữ liệu quy mô lớn mà là một phần quan trọng của sự thành công của các mô hình phân tán.
Mức độ chất lượng trong việc tạo ra các hình ảnh 2D đã đạt đến một điểm mà nó đang trở nên khó phân biệt giữa các mô hình được tạo ra bằng AI với các mô hình thực tế. Tuy nhiên, khi chúng ta thêm chiều thứ ba và chuyển sang việc tạo ra hình ảnh 3D, điều này không thể được như vậy, rất tiếc. Các mô hình tạo hình 3D vẫn kém hơn so với bối cảnh 2D của chúng.
Mô hình hóa 3D là một không gian đầu ra đáng kể vì nó yêu cầu nhiều công việc hơn phải được thực hiện. Đảm bảo tính nhất quán ở chiều 3D là một nhiệm vụ cực kỳ thách thức, và hơn nữa, sự thiếu hụt các tập dữ liệu mô hình chữ 3D quy mô lớn khiến cho việc huấn luyện một mô hình sản sinh trở nên đơn giản không khả thi. Do đó, các nỗ lực hiện có tập trung vào vòng qua các yêu cầu bằng cách biến dạng hình dạng template bằng cách sử dụng mục tiêu CLIP, nhưng các hình dạng 3D thu được không đáp ứng được yêu cầu về hình học và diện mạo.
Sau đó, đến DreamFusion. Nó sử dụng các mô hình phân tán từ văn bản đến hình ảnh để giám sát mô hình hóa 3D từ các thông điệp văn bản. Tuy nhiên, phương pháp này có xu hướng tạo ra màu quá tải và đại diện cho cảnh 3D dưới dạng Neural Radiance Field (NeRF), điều này là không thực tế cho việc đường ống đồ họa máy tính chuẩn.
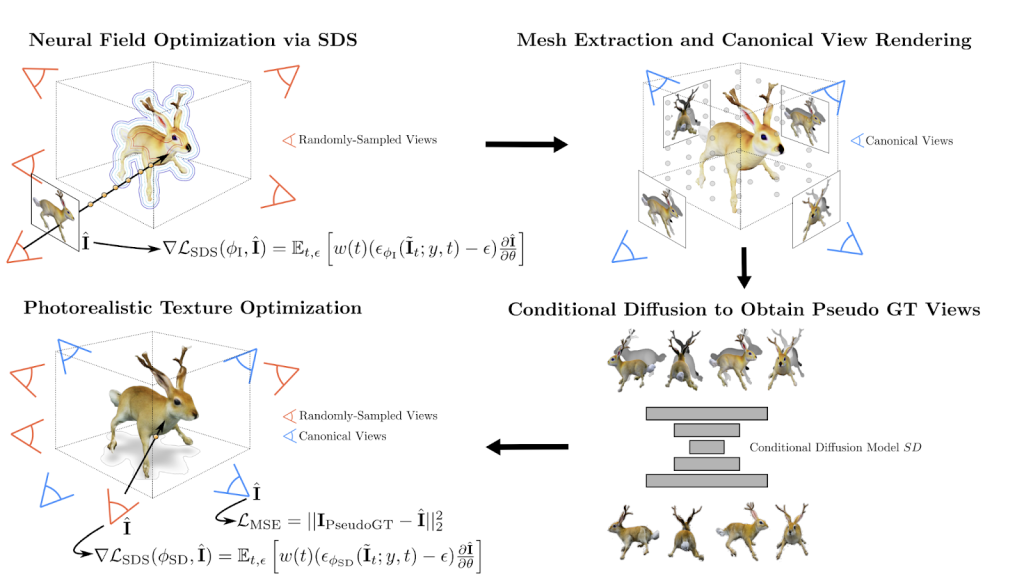
Vậy, cách giải quyết vấn đề này là gì? Làm thế nào chúng ta có thể có một mô hình AI có thể tạo ra lưới 3D thực tế? Câu trả lời là TextMesh.
Tổng quan về TextMesh. Nguồn: https://arxiv.org/pdf/2304.12439.pdf
TextMesh là một phương pháp mới cho việc tạo hình 3D từ các thông điệp văn bản tạo ra nội dung 3D photorealistic dưới dạng các lưới 3D chuẩn. TextMesh sửa đổi DreamFusion để mô hình bức xạ dưới dạng hàm khoảng cách có dấu (SDF) để cho phép trích xuất bề mặt dễ dàng dưới dạng tập hợp cấp 0 của khối lượng được thu được. Ngoài ra, TextMesh lại sửa đổi kiểu dáng đầu ra bằng cách tận dụng một mô hình suy biến khác, được điều kiện hóa bằng màu sắc và độ sâu từ lưới.

TextMesh cũng đưa ra một phương pháp tái texturing đa quan điểm và có điều kiện cho lưới mới lạ mở rộng để cho phép tạo ra các mô hình lưới 3D photorealistic. Texture được tinh chỉnh được huấn luyện trên một số quan điểm đồng thời thông qua mô hình suy biến để đảm bảo các chuyển tiếp mượt mà.
Kết quả mẫu của TextMesh. Các kết quả tương tác có thể được xem trên trang web. Nguồn: https://arxiv.org/pdf/2304.12439.pdf
Nhìn chung, TextMesh sửa đổi DreamFusion để mô hình bức xạ dưới dạng SDF để điều chỉnh mô hình cho việc trích xuất lưới. Nó đưa ra một phương pháp tái texture mới lạ được điều kiện hóa lưới. TextMesh có thể tạo ra các lưới 3D được cải thiện đáng kể so với các phương pháp trước đó để đạt tính thực tế và có thể sử dụng trực tiếp trong các đường ống đồ họa máy tính và các ứng dụng trong lĩnh vực AR hoặc VR.
Hãy tham khảo Dự án này. Đừng quên tham gia vào 21k ML SubReddit của chúng tôi, Kênh Discord, và Bản Tin Thư Điện Tử, nơi chúng tôi chia sẻ tin tức nghiên cứu AI mới nhất, các dự án AI tuyệt vời và hơn thế nữa. Nếu bạn có bất kỳ câu hỏi nào liên quan đến bài viết trên hoặc nếu chúng tôi đã bỏ sót điều gì, hãy gửi email đến chúng tôi tại [email protected]
🚀 Kiểm Tra 100 Công Cụ AI Trong AI Tools Club