IBM công bố ngăn xếp phát triển phần mềm Watsonx của mình vào tháng 5, và hôm nay, họ đã bắt đầu chuyển giao nó cho khách hàng. Chúng ta muốn biết chính xác nó là cái gì. Vì vậy, chúng tôi đã liên hệ với Sriram Raghavan, phó chủ tịch chiến lược trí tuệ nhân tạo và định hướng tại IBM Research, để hiểu rõ Watsonx là gì và tại sao nó quan trọng đối với việc thương mại hóa mô hình ngôn ngữ lớn.

Hãy nói về lý do trước khi nói về cái gì.
Theo Raghavan, có bốn làn sóng trí tuệ nhân tạo khác nhau. Và mặc dù IBM đã cố gắng hết sức với ngăn xếp phần mềm Watson của mình, vốn nổi tiếng được sử dụng đầu tiên để chơi trò chơi Jeopardy! và đánh bại các chuyên gia người thật vào tháng 2 năm 2011, nó thực sự không phải là một thành công thương mại trong lĩnh vực doanh nghiệp trong hai làn sóng đầu tiên.
Nhưng với làn sóng trí tuệ nhân tạo hiện tại, theo Raghavan, các doanh nghiệp, chính phủ và các tổ chức giáo dục - nhiều trong số chúng là khách hàng của các hệ thống và phần mềm hệ thống của IBM - không sẽ lỡ hẹn lần này.
Hầu hết các doanh nghiệp chắc chắn đã bị bỏ lại sau khi làn sóng đầu tiên của trí tuệ nhân tạo, với hệ thống chuyên gia được mô tả và xây dựng gần 60 năm trước, đặc biệt là Dự án Lập trình Heuristic của Stanford do Edward Feigenbaum dẫn đầu. Những hệ thống này được tạo thành từ các cây khổng lồ của các câu lệnh nếu...thì mà là một trình điều khiển luật, dựa trên một cơ sở tri thức và một trình điều khiển suy luận áp dụng các quy tắc vào cơ sở tri thức đó để đưa ra quyết định trong một lĩnh vực được xác định chặt chẽ, chẳng hạn như y học. Đây là một phương pháp rất ngữ nghĩa và biểu tượng với rất nhiều mã hóa của con người.
Cách tiếp cận thống kê đối với trí tuệ nhân tạo đã có từ đầu - trong bài báo nổi tiếng về Turing năm 1950, từ đó ta có được kiểm tra Turing - nhưng chúng đã lùi về sau trong thời gian dài so với hệ thống chuyên gia do thiếu dữ liệu và thiếu xử lý để xử lý các dữ liệu khổng lồ đó. Nhưng với học máy trong thập kỷ 2010 - làn sóng thứ hai của trí tuệ nhân tạo - phân tích thống kê của các bộ dữ liệu khổng lồ được sử dụng để tìm ra mối quan hệ giữa dữ liệu và tự động tạo ra thuật toán.
Trong thời kỳ thứ ba của trí tuệ nhân tạo, học sâu, mạng thần kinh - các thuật toán mô phỏng cách hoạt động của não người theo một cách nào đó, mà chính nó cũng là một máy thống kê nếu bạn thực sự muốn nghĩ về nó (và thậm chí nếu bạn không muốn) - được sử dụng để trừu tượng hóa dữ liệu đầu vào, và càng sâu vào mạng - có nghĩa là số lượng cấp convolutions và số lượng biến đổi là sâu.
Trong thời kỳ thứ tư, gồm các mô hình ngôn ngữ lớn - thường được gọi là mô hình cơ sở - sự biến đổi và sâu hơn đã được đưa đến một cực độ, và phần cứng chạy nó cũng vậy, và do đó là hành vi mới mẻ mà chúng ta đang thấy với GPT, BERT, PaLM, LLaMA và những mô hình biến đổi khác.
Cá nhân chúng tôi không coi chúng như các thời kỳ cả, mà có thể coi chúng là các giai đoạn tăng trưởng, tất cả có liên quan đến nhau và nằm trên một trục liên tục. Một hạt giống chỉ là một cái cây nhỏ chờ đợi xảy ra.
Dù bạn muốn vẽ như thế nào, như Raghavan hoặc không, các bộ biến đổi đang là nền tảng của các mô hình ngôn ngữ lớn (LLM) và các hệ thống gợi ý học sâu (DLRM), và chúng lại biến đổi doanh nghiệp. Và kỹ thuật học máy chung hơn cũng sẽ được các doanh nghiệp sử dụng cho nhận dạng hình ảnh và giọng nói và các nhiệm vụ khác vẫn quan trọng.
"Những mô hình cơ bản cho phép trí tuệ nhân tạo sáng tạo", Raghavan nói với The Next Platform. "Nhưng một cách thú vị, mô hình cơ bản cũng tăng tốc và cải thiện đáng kể những gì bạn có thể làm với trí tuệ nhân tạo không sáng tạo và quan trọng là không bỏ qua những gì chúng sẽ làm cho các nhiệm vụ không sáng tạo. Và lí do chúng tôi đang kết hợp Watsonx là chúng tôi muốn một môi trường lai hợp lý đơn, chuyên nghiệp mà trong đó khách hàng có thể thực hiện tốt nhất cả học máy và mô hình cơ bản. Đó là điểm mạnh của nền tảng này.
Việc thuyết minh cụ thể về những điều có hoặc không có trong nền tảng trí tuệ nhân tạo của IBM hoặc bất kỳ nhà cung cấp phần mềm nào khác đều rất phức tạp. Chúng tôi vẫn là người duy nhất đã tiết lộ cách hệ thống Watson gốc được xây dựng. Thực chất, nó hoàn toàn là một cụm Hadoop Apache để lưu trữ khoảng 200 triệu trang văn bản liên kết với khung quản lý dữ liệu Apache UIMA cùng hơn 1 triệu dòng mã tùy chỉnh để đáp ứng các câu hỏi bằng động cơ DeepQA - tất cả đang chạy trên một cụm Power7 khá khiêm tốn với 2.880 nhân và 11.520 luồng và 16 TB bộ nhớ chính. Điều này yếu hơn rất nhiều so với một GPU duy nhất ngày nay, mặc dù bộ nhớ ít hơn rất nhiều (chính xác hơn là hai bậc trên thang đo so với khả năng tính toán, bộ nhớ và băng thông của bộ nhớ).
Các thành phần của bộ công cụ Watson AI đã trải qua nhiều phiên bản và biến thể trong thập kỷ trước đây kể từ khi máy mang tên Watson này vượt qua con người, và bộ công cụ Watsonx mới này sẽ hoạt động với nhiều công cụ hiện có như môi trường phát triển Watson Studio.
Ảnh về sơ đồ khối của IBM Watsonx (Liên kết đến hình ảnh)
Bộ công cụ Watsonx bao gồm ba phần.
Phần đầu tiên là Watsonx.ai, bao gồm một bộ sưu tập các mô hình nền tảng được phát triển bởi IBM Research hoặc là mã nguồn mở. Hiện tại, bộ công cụ có hơn hai mươi mô hình khác nhau mà IBM Research đã đưa ra và chúng được nhóm lại bằng tên các loại đá biến đổi: Slate (Đá phiến), Sandstone (Đá cuội), và Granite (Đá cẩm thạch).
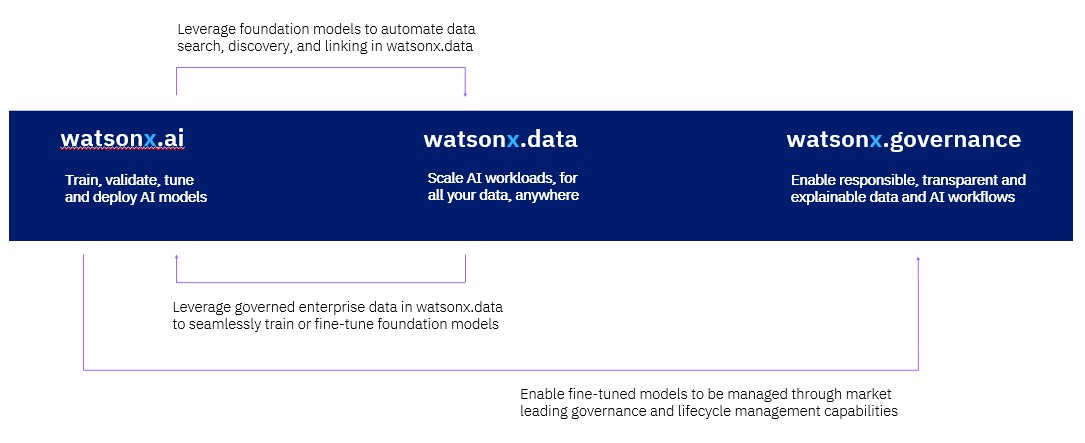
“Các mô hình Slate là các mô hình mã hóa cổ điển,” Raghavan giải thích. “Đây là các mô hình bạn muốn có một mô hình cơ bản, nhưng bạn không muốn làm AI sinh sản. Các mô hình này xuất sắc trong việc phân loại và trích xuất thực thể. Chúng không phải là nhiệm vụ sinh sản, nhưng chúng phù hợp với mục đích sử dụng và có một số trường hợp sử dụng mà chúng sẽ hoạt động. Mô hình Sandstone là các mô hình mã hóa/mã giải, chúng mang lại sự cân bằng tốt giữa cả nhiệm vụ sinh sản và không sinh sản. Với các mô hình Sandstone đủ lớn, bạn có thể làm kỹ thuật gợi ý và tất cả những điều thú vị mà bạn đang nghe về ChatGPT. Và sau đó, Granite sẽ là các mô hình mã giải một mình.”
Bộ công cụ Watsonx.ai tương thích với API của thư viện Hugging Face transformer, được viết bằng Python, để cả huấn luyện và dự đoán trí tuệ nhân tạo. Việc hỗ trợ API này của Hugging Face rất quan trọng vì số lượng mô hình được viết trên nền tảng Hugging Face đang tăng vọt và API này đang trở thành một tiêu chuẩn về di động. Những khách hàng đang nghĩ đến tương lai sẽ không sử dụng Virtex tại Google hay SageMaker tại Amazon Web Services, mà sẽ tìm một mô hình nhất quán có thể triển khai bên trong hoặc trên bất kỳ đám mây nào.
PyTorch là khung trí tuệ nhân tạo cơ bản của Watsonx. IBM đã “đặt cược” vào cả ngôn ngữ Python và khung PyTorch, như Raghavan đã nói, và đang làm việc rất gần với Meta Platforms sau khi PyTorch được phát hành tự do trong Linux Foundation.
“Với PyTorch, chúng tôi đang làm việc để cải thiện hiệu suất huấn luyện và giảm chi phí dự đoán,” Raghavan cho biết. “Chúng tôi có thể chứng minh rằng trên một kiến trúc đám mây thuần túy, với mạng Ethernet tiêu chuẩn và không cần đến InfiniBand tùy chỉnh, bạn có thể huấn luyện các mô hình nền tảng với 10 tỷ hoặc 15 tỷ tham số một cách tốt, điều này rất tuyệt vì khách hàng của chúng tôi quan tâm đến chi phí. Không phải ai cũng có thể chi 1 tỷ đô la vào một siêu máy tính.”
(Không đùa đấy.)
IBM Research đã tạo ra một bộ dữ liệu để huấn luyện các mô hình nền tảng cơ bản của mình với hơn 1 nghìn tỷ mã thông tin, đó là một lượng dữ liệu lớn theo mọi tiêu chuẩn. (Mã thông tin thông thường là một đoạn từ hoặc từ ngắn có khoảng bốn ký tự trong ngôn ngữ tiếng Anh.) Tin đồn cho biết Microsoft và OpenAI có một bộ dữ liệu khoảng 13 nghìn tỷ mã thông tin cho GPT-4 và 1,8 nghìn tỷ tham số. So với đó, PaLM của Google có 540 tỷ tham số và MegaTron của Nvidia có 530 tỷ tham số; chúng ta không biết kích thước của bộ dữ liệu này. Raghavan cho biết, khách hàng của IBM không cần những thứ quá lớn như vậy.
Có rất nhiều khách hàng muốn lấy một mô hình cơ bản và thêm 100.000 tài liệu để có một mô hình cơ bản riêng phù hợp với các trường hợp sử dụng. Chúng tôi muốn cho phép họ làm điều đó với chi phí rẻ nhất có thể, vì vậy chúng tôi đang làm việc với cộng đồng Python và Hugging Face để tối ưu hóa giải quyết vấn đề cảu việc suy luận và đào tạo. Chúng tôi cũng có quan hệ đối tác với cộng đồng Ray, vốn rất hiệu quả trong việc tiền xử lý dữ liệu, đánh giá hiệu năng và xác thực. Chúng tôi cũng đã làm việc giữa IBM Research và Red Hat để đưa tất cả các kỹ thuật này lên OpenShift, và chúng tôi đang làm việc với cộng đồng PyTorch để cải thiện hiệu suất của nó trên nền tảng Kubernetes và cải thiện cách chúng tôi thực hiện việc lưu trữ đối tượng."
Mảnh thứ hai của bộ công cụ trí tuệ nhân tạo của IBM là Watsonx.data, được IBM quảng cáo là một phương án thay thế cho Hadoop. Đó là sự kết hợp giữa các dự án Apache - lưu trữ liên tục Ranger, dữ liệu trong bộ nhớ Spark, định dạng bảng Iceberg, định dạng cột Parquet với việc ghi và đọc và Orc cho việc đọc dữ liệu nặng tối ưu hóa cho giao diện Hive SQL dành cho các kho dữ liệu được đặt lên Hadoop, và môi trường SQL phân tán Presto. (Hive và Presto đến từ Facebook trước đây, hiện tại là Meta Platforms, giống như PyTorch.)

Mảnh thứ ba của bộ công cụ Watsonx là Watsonx.governance, và với tư cách là một nhà cung cấp hệ thống và phần mềm doanh nghiệp, IBM rất quan tâm đến quản lý và bảo mật - như khách hàng của họ. (Mắt chúng tôi trĩu mắt khi nói về quản lý, nhưng chúng tôi vẫn biết ơn điều đó. . . . )
Đây là điểm quan trọng: Đây có thể cuối cùng là bộ công cụ trí tuệ nhân tạo Watson mà Big Blue có thể bán được.
Trong quá khứ xa xôi vào năm 1998, khi làn sóng Dot Com chỉ mới bắt đầu nổi lên, IBM đã quản lý hạ tầng công nghệ thông tin cho Thế vận hội Mùa đông tại Nagano, Nhật Bản. Vào thời điểm đó, máy chủ Apache đã ba năm tuổi, nó không tự co dãn tốt và không ổn định. Big Blue cần nó phải vậy, vì vậy nó đã tạo điểm nhấn. Sớm sau đó, máy chủ Apache này đã kết hợp với phần mềm phục vụ ứng dụng Java, và các khách hàng doanh nghiệp của IBM đã xếp hàng mua sản phẩm - được gọi là WebSphere - trên rất nhiều máy của họ. WebSphere đã tạo nên sức cạnh tranh với Oracle WebLogic và RedHat JBoss trong hai thập kỷ và nắm giữ một số lượng khổng lồ tỷ đô la doanh thu và lợi nhuận cho IBM trong thời gian đó.
Big Blue rõ ràng muốn lặp lại lịch sử đó.
Đặc trưng, phân tích và các câu chuyện từ tuần trực tiếp từ chúng tôi đến hộp thư đến của bạn mà không có gì ở giữa.Hãy đăng ký ngay