Trong khi LLMs như ChatGPT có thể cho bạn bất kỳ văn bản nào bạn muốn và các trình tạo đồ họa như Stable Diffusion sẽ tạo ra một hình ảnh dựa trên lời nhắc, AI text-to-video vẫn là một lĩnh vực mới nổi. Tuần trước, chúng tôi đã báo cáo về một quảng cáo Pizza AI sử dụng một công cụ text-to-video gọi là Runway Gen-2 (mở trong tab mới) cho video của nó. Tuy nhiên, hiện tại, Runway Gen-2 đang ở phiên bản beta chỉ mời. Vì vậy, trừ khi bạn được mời, bạn không thể thử nghiệm nó.
May mắn thay, trên Hugging Face (cổng phát triển AI hàng đầu), có một công cụ hoàn toàn miễn phí và dễ sử dụng được gọi là NeuralInternet Text-to-Video Playground, nhưng nó chỉ giới hạn trong khoảng hai giây, đủ cho một GIF động. Bạn thậm chí không cần có tài khoản Hugging Face để sử dụng nó. Đây là cách sử dụng.
Cách tạo ra một đoạn Video-Text AI 2 giây:
1. Điều hướng đến Text-to-Video Playground (mở trong tab mới) trên trình duyệt của bạn.
2. Nhập một lời nhắc vào hộp lời nhắc hoặc thử một lời nhắc mẫu ở dưới trang (ví dụ: "Một phi hành gia đang cưỡi ngựa")

(Image credit: Tom's Hardware)
3. Nhập số Seed của bạn. Seed là một số (từ -1 đến 1.000.000) mà AI sử dụng làm điểm khởi đầu để tạo ra hình ảnh. Điều này có nghĩa là nếu bạn sử dụng Seed là 1, bạn nên nhận được cùng một kết quả mỗi lần với cùng một lời nhắc. Tôi khuyên bạn nên sử dụng Seed là -1, để thu được một số Seed ngẫu nhiên mỗi lần.


(Image credit: Tom's Hardware)
4. Nhấp vào Run.
(Image credit: Tom's Hardware)
Sau đó, Text-to-Video Playground sẽ mất vài phút để tạo ra kết quả. Bạn có thể xem tiến độ bằng cách nhìn vào cửa sổ Kết quả. Tùy thuộc vào lượng lưu lượng truy cập của máy chủ, nó có thể mất thời gian tính toán nhiều hơn.
5. Nhấn vào nút play để phát video của bạn.
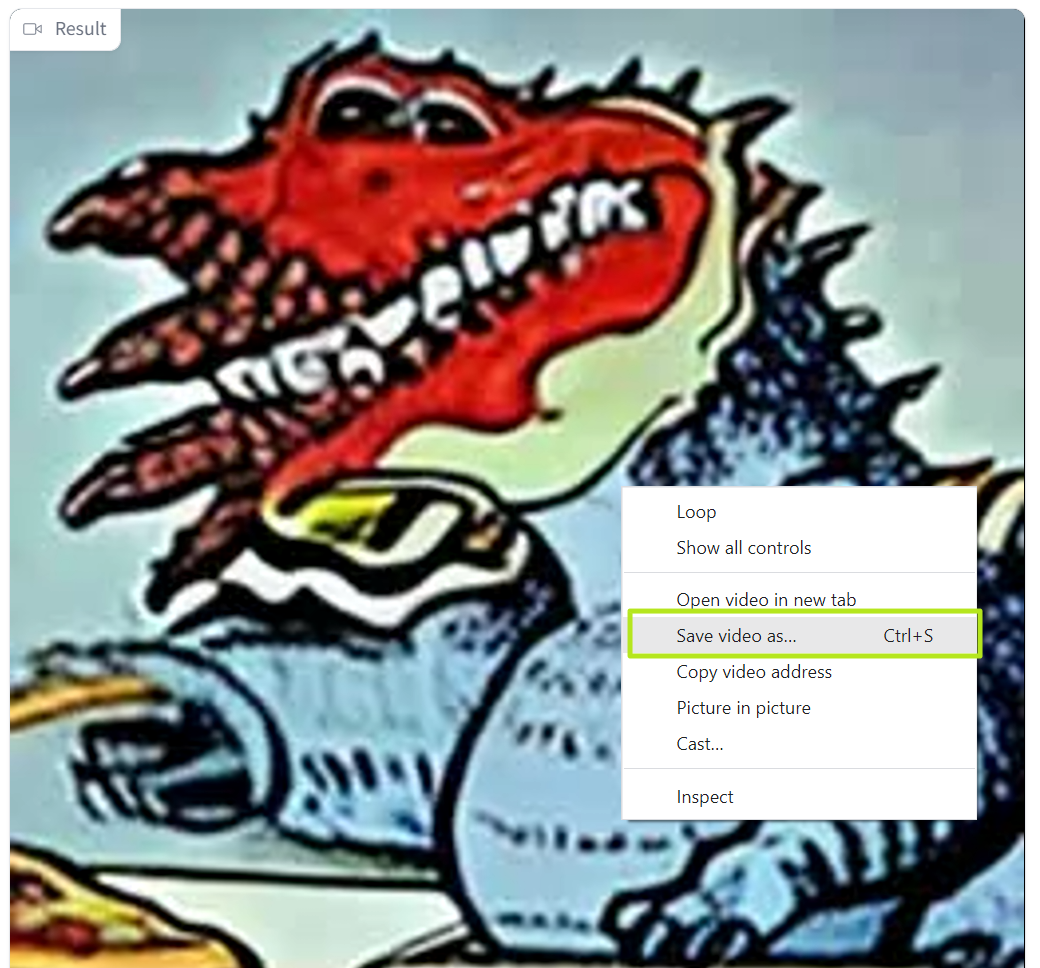
6. Nhấp chuột phải vào video của bạn và chọn Save Video as để tải video xuống (dưới dạng MP4) về PC của bạn.
Mô hình đang sử dụng và kết quả:

Playground Text-to-Video đang sử dụng một mô hình text-to-video từ một công ty Trung Quốc được gọi là ModelScope, khẳng định rằng mô hình của họ có 1,7 tỷ thông số (mở ở tab mới). Giống như nhiều mô hình AI xử lí hình ảnh, mô hình ModelScope có một số giới hạn, vượt quá thời gian chạy chỉ hai giây.
Đầu tiên, rõ ràng là tập dữ liệu huấn luyện lấy từ nhiều hình ảnh web khác nhau, bao gồm một số hình ảnh có bản quyền và một logo Shutterstock trên đối tượng trong video. Shutterstock là một nhà cung cấp hình ảnh không có bản quyền hàng đầu yêu cầu phải trả phí, nhưng dường như các dữ liệu huấn luyện chỉ lấy các hình ảnh của Shutterstock mà không có sự cho phép.
Watermark Shutterstock. Vòng tròn là của tôi (Credit ảnh: Tom's Hardware)
Thêm vào đó, không phải mọi thứ đều trông như nó nên. Ví dụ, người hâm mộ kaiju sẽ nhận ra rằng video Godzilla ăn pizza của tôi dưới đây chỉ cho thấy một con quái vật là một con thằn lằn màu xanh lớn nhưng không có bất kỳ đặc điểm đặc trưng nào của con quái vật Nhật Bản được yêu thích của tất cả mọi người.

Video này được tạo bằng công cụ chơi text-to-video và sau đó chuyển đổi thành GIF để hiển thị dễ dàng ở đây. (Credit ảnh: Future)
Cuối cùng và có thể không cần phải nói nhưng, các video này không có âm thanh. Việc sử dụng tốt nhất cho chúng có lẽ là chuyển đổi chúng thành GIF động bạn có thể gửi cho bạn bè của mình. Hình ảnh trên là một GIF động mà tôi đã làm từ một trong hai video Godzilla ăn pizza hai giây của mình.

Nếu bạn muốn tìm hiểu thêm về việc sáng tạo trong AI, hãy xem các bài viết của chúng tôi về cách sử dụng Auto-GPT để tạo ra một đại lý tự động hoặc cách sử dụng BabyAGI.
Nhận ngay tin tức nóng hổi, đánh giá sâu sắc và những lời khuyên hữu ích.