Như chúng tôi đã chỉ ra một năm trước đó khi một số chuyên gia silicon quan trọng bị thuê từ Intel và Broadcom để làm việc cho Meta Platforms, công ty trước đây được biết đến với tên gọi Facebook luôn là địa điểm rõ ràng nhất để tạo ra chip tùy chỉnh. Trong số tám công ty Internet lớn nhất trên thế giới, đồng thời là các nhà mua công nghệ thông tin lớn nhất trên thế giới, Meta Platforms là một trong số ít các doanh nghiệp thuộc hạng hyperscaler thuần túy và không bán khả năng hạ tầng trên đám mây.

Và vì vậy, Meta Platforms sở hữu các chuỗi phần mềm của mình, từ đầu đến đuôi, và có thể làm bất cứ điều gì để tạo ra phần cứng để điều khiển chúng. Và nó đủ giàu để làm điều đó và chi tiêu đủ tiền cho silic của nó và người để điều chỉnh phần mềm cho nó rằng nó không thể không tiết kiệm được một khoản tiền lớn bằng cách kiểm soát nhiều hơn về nòng cốt chip của mình.
Meta Platforms đang giới thiệu chip AI inference và mã hóa video tự chế của mình tại sự kiện AI Infra @ Scale của nó, cũng như đang nói về triển khai của Research Super Computer của nó, các thiết kế trung tâm dữ liệu mới để phục vụ công việc AI nặng, và sự tiến hóa của các khung AI của nó. Chúng tôi sẽ phân tích nội dung này chi tiết trong vài ngày tới, cùng với việc thực hiện phỏng vấn với Alexis Black Bjorlin, phó chủ tịch cơ sở hạ tầng tại Meta Platforms và một trong những nhà lãnh đạo quan trọng được bổ sung vào đội silicon tùy chỉnh tại công ty một năm trước. Nhưng hiện tại, chúng tôi sẽ tập trung vào Meta Training và Inference Accelerator, hoặc viết tắt là MTIA v1.
Với tất cả các công ty chú ý rằng họ sẽ bán rất nhiều GPU hoặc NNPs cho Facebook, chúng tôi xin cảnh báo rằng đó không phải là việc dễ dàng.
Về lâu dài, CPUs, DPUs, và switch và routing ASICs có thể được thêm vào danh sách các thành phần bán dẫn không được mua bởi Meta Platforms. Và nếu Meta Platforms thực sự muốn tạo ra rất nhiều sự rối loạn, nó có thể bán silic của riêng mình cho người khác... Điều kỳ lạ đã xảy ra. Như cuộc sống đồ chơi của đá lót trong năm 1975, chỉ để đưa ra một ví dụ.
NNP và GPU không thể xử lý được tải trọng với chi phí tổng quát tốt
Bộ não nhân tạo MTIA được khởi động vào năm 2020, ngay khi đại dịch coronavirus làm tất cả mọi thứ điên cuồng và AI đã vượt khỏi khả năng nhận diện hình ảnh và chuyển đổi từ tiếng nói sang văn bản để có khả năng tạo ra các mô hình ngôn ngữ lớn, có vẻ như chúng biết làm nhiều điều mà chúng không được dự định sẽ làm. Mô hình khuyến nghị học sâu, hoặc DLRMs, là một vấn đề tính toán và bộ nhớ rất phức tạp hơn so với LLMs do sự phụ thuộc của chúng vào nhúng - một loại biểu đồ đại diện cho ngữ cảnh của tập dữ liệu - mà phải được lưu trữ trong bộ nhớ chính của các thiết bị tính toán chạy các mạng lưới thần kinh. LLMs không có nhúng, nhưng DLRMs lại có, và bộ nhớ đó là lý do tại sao bộ nhớ CPU của máy chủ hoặc việc kết nối nhanh và có băng thông cao giữa CPUs và các bộ gia tốc quan trọng hơn đối với DLRMs so với LLMs. Joel Coburn, một kỹ sư phần mềm tại Meta Platforms, đã cho thấy biểu đồ này là một phần trong sự kiện AI Infra @ Scale mà mô tả cách các mô hình DLRM inference tại công ty đã phát triển về kích thước và yêu cầu tính toán trong ba năm qua và cách công ty dự kiến chúng sẽ phát triển trong mười tám tháng tiếp theo.
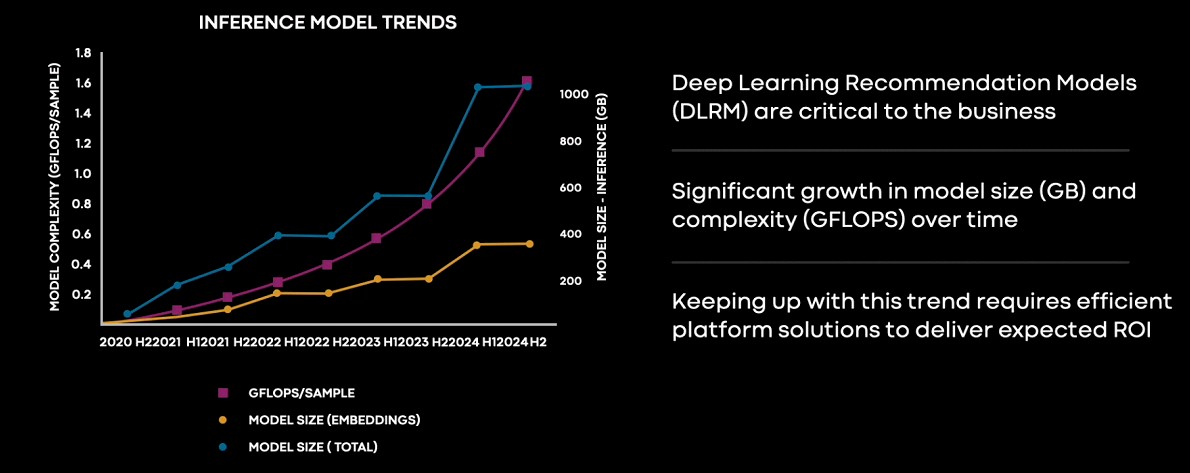
Dù chưa từng xem loại biểu đồ này cho DLRMs, nhưng đây là loại biểu đồ chúng ta thường xem. Đây là một biểu đồ đáng sợ, nhưng không đáng sợ như cái này:
Ở phía trái của biểu đồ, Meta Platforms đang thay thế việc đoán nghĩa dựa trên CPU bằng bộ xử lý mạng nơ-ron cho đoán nghĩa, hay NNPIs, trong các nền tảng máy chủ nhỏ Yosemite mà chúng ta đã nói về từ lâu trong năm 2019. Việc đoán nghĩa dựa trên CPU vẫn đang diễn ra, nhưng khi các mô hình DLRM trở nên phình to, chúng đã vượt quá giới hạn của NNPIs, sau đó Meta Platforms đã phải tới sử dụng GPU để đoán nghĩa. Chúng tôi cho rằng đây không phải là cùng các GPU được sử dụng để đào tạo trí tuệ nhân tạo, nhưng là các thẻ PCI-Express như T4 và A40 của Nvidia, nhưng Coburn không cụ thể. Và sau đó, việc này trở nên ngày càng đắt đỏ hơn khi nhu cầu đoán nghĩa được tăng cường.
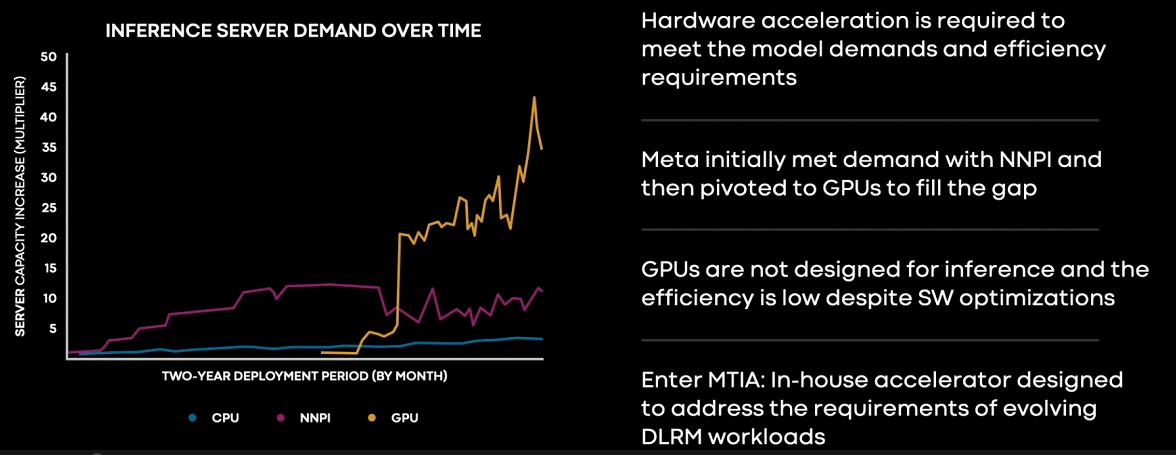
"Bạn có thể thấy yêu cầu cho việc suy luận nhanh chóng đã vượt xa khả năng của NNPI và Meta đã chuyển đổi sang GPU vì chúng cung cấp sức mạnh tính toán lớn hơn để đáp ứng nhu cầu ngày càng tăng," Coburn giải thích trong buổi ra mắt MTIA. "Nhưng dường như GPUs không được thiết kế với suy đoán trong tâm trí và hiệu suất của chúng thấp cho các mô hình thực tế mặc dù tối ưu phần mềm đáng kể. Và điều này khiến chúng trở nên thử thách và đắt đỏ để triển khai và thực hành."
Chúng tôi nghiêm chỉnh nghi ngờ rằng Nvidia sẽ tranh luận rằng Meta Platforms đang sử dụng thiết bị sai cho DLRMs, hoặc nó có thể đã giải thích cách mà tổ hợp CPU "Grace" và GPU "Hopper" sẽ giải cứu ngày mai. Nhưng tất cả điều đó đều không quan trọng bởi vì Meta Platforms muốn kiểm soát vận mệnh của mình trong silicon chính như nó đã làm từ năm 2011 khi ra mắt dự án Open Compute Project để chia sẻ các thiết kế máy chủ và trung tâm dữ liệu miễn phí.
Điều đó dẫn đến câu hỏi: Liệu Facebook có chia sẻ mã RTL và thiết kế cho thiết bị MTIA không?
Đặt cược vào RISC-V cho MTIA
Facebook đã từng là người ủng hộ chủ trương phần mềm và phần cứng mã nguồn mở mạnh mẽ, và sẽ là một bất ngờ lớn nếu Meta Platforms không chấp nhận kiến trúc RISC-V cho trình kích hoạt MTIA. Nó dựa trên một yếu tố xử lý RISC-V hai nhân, được bọc quanh bằng một số lượng lớn các thành phần nhưng không quá nhiều để nó không thể chứa trong một chip 25 watt và một thẻ ngoại vi kép 35 watt.

Dưới đây là các thông số cơ bản của chip MTIA v1:
Bởi vì nó có tần số thấp, chip MTIA v1 được sử dụng một lượng công suất khá thấp và được thực hiện trong quy trình 7 nanomet, có nghĩa là chip nhỏ hơn có thể hoạt động mà không nóng. Những quy trình đó là đắt tiền hơn, và có lẽ là điều mà chúng ta sẽ tiết kiệm cho một ngày sau - và một thế hệ thiết bị cho việc đào tạo và suy luận riêng biệt hoặc cùng với nhau như Google làm với TPUs của mình - khi những quy trình này được trưởng thành và rẻ hơn.
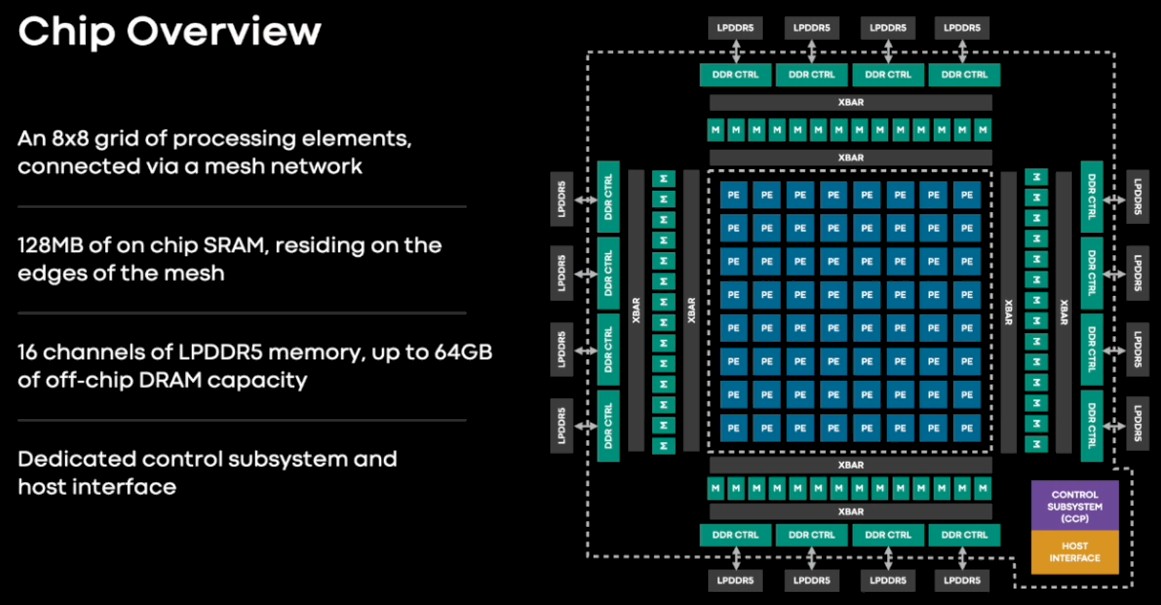
Vi chip suy luận MTIA v1 có một lưới gồm 64 yếu tố xử lý có bộ nhớ SRAM 128MB được bọc quanh chúng có thể được sử dụng như lưu trữ chính hoặc cho bộ nhớ đệm. Nó còn hỗ trợ 16 bộ điều khiển bộ nhớ DDR5 tiết kiệm điện và được sử dụng trong các laptop và cũng được sử dụng trong CPU máy chủ Arm "Grace" của Nvidia sắp ra mắt. Sáu mươi bốn kênh bộ nhớ LPDDR5 này có thể cung cấp lên đến 64 GB bộ nhớ bên ngoài, phù hợp để lưu trữ các nhúng mập mạp cần thiết cho DLRMs. (Chi tiết hơn về điều này sẽ được đề cập sau.)
64 yếu tố xử lý này dựa trên một cặp nhân RISC-V, một thông thường và một có phần mở rộng toán học vector. Mỗi yếu tố xử lý có 128KB bộ nhớ địa phương và các đơn vị chức năng cố định để thực hiện toán học FP16 và INT8, xử lý hàm phi tuyến, và di chuyển dữ liệu.
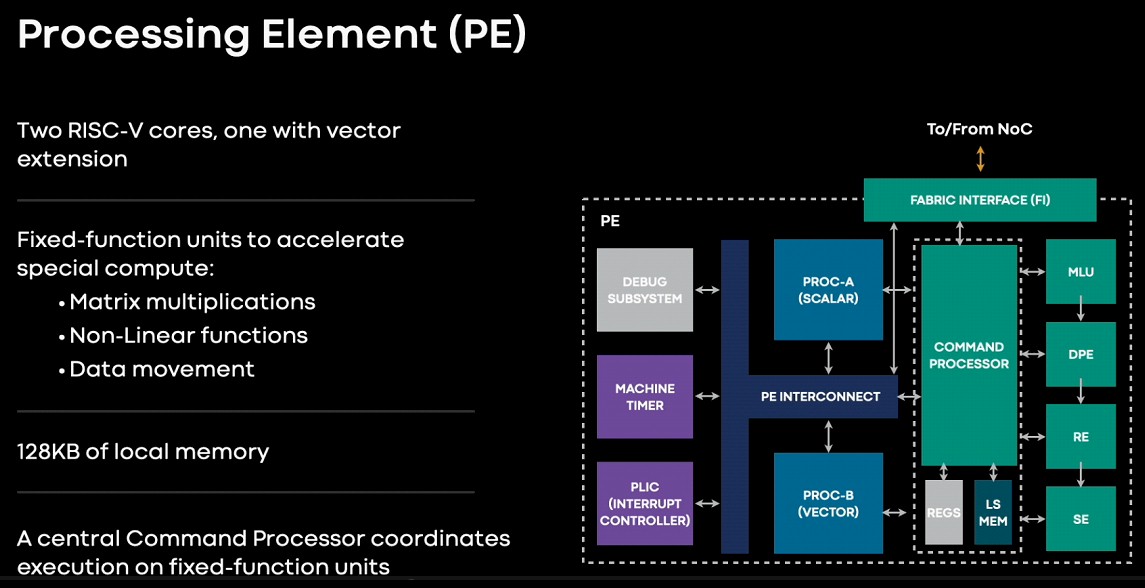
Đây là giao diện MTIA v1:
Không có cách nào để đặt quạt lên trên vi mạch và có đến một tá yếu tố xử lý này vừa khít bên trong máy chủ Yosemite V3 được. Có lẽ chỉ để thể hiện tỉ lệ?

Điều thú vị trong thiết kế máy chủ MTIA là được kết nối thông qua mạng lá/chân PCI-Express trong máy chủ Yosemite. Nó không chỉ cho phép MTIA kết nối với máy chủ mà còn với nhau và với 96GB DRAM máy chủ chứa được những bản nhúng lớn hơn nếu cần thiết. (Giống như Nvidia sẽ làm với Grace-Hopper.) Toàn bộ máy chủ tiêu thụ 780 watt cho mỗi hệ thống, tức hơi hơn 700 watt của một GPU Hopper SXM5 đang chạy full tilt.
Cụm điều khiển Nvidia H100 có thể xử lý 2.000 teraop với độ chính xác INT8 trong 700 watt cho thiết bị, nhưng nền tảng suy luận Yosemite của Meta Platforms có thể xử lý 1.230 teraops với 780 watt cho hệ thống. Một DGX H100 tiêu thụ 10.200 watt với bảy GPU, tức là 16.000 teraops cho 1,57 teraops mỗi watt. MTIA tiêu thụ 1,58 teraops mỗi watt và được hiệu chỉnh cho khung DLRM và PyTorch của Meta Platform - và sẽ được hiệu chỉnh thêm. Chắc chắn rằng chi phí của mỗi đơn vị công tác cho khung MTIA sẽ rẻ hơn rất nhiều so với hệ thống DGX H100 - nếu không, Meta Platforms sẽ không đưa nó lên.
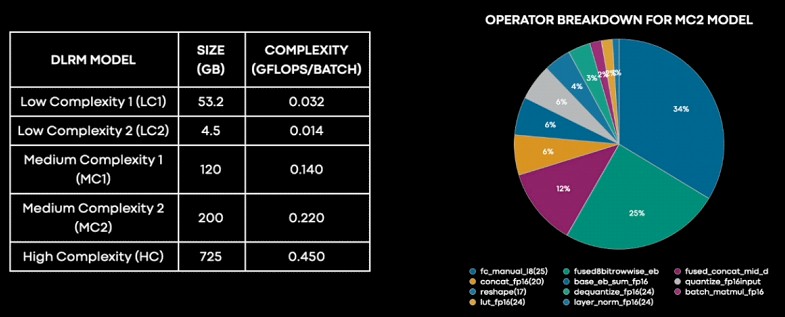
Tất nhiên, chỉ số tốc độ và dữ liệu thô không phải là cách tốt nhất để so sánh các hệ thống. Các DLRM có các cấp độ phức tạp và kích thước mô hình khác nhau, và không phải cái nào cũng tốt. Đây là cách phân chia DLRM bên trong Meta Platforms:
"Chúng tôi có thể thấy rằng phần lớn thời gian thực tế được dành cho các lớp kết nối đầy đủ, theo sau là các lớp phục hồi nhúng và sau đó là các hoạt động dài như concat, transpose, quantize và dequantize và những cái khác," giải thích Roman Levenstein, giám đốc kỹ thuật của Meta Platforms. "Việc phân chia này cũng cho chúng tôi cái nhìn về chỗ và cách mà MTIA hiệu quả hơn. MTIA có thể đạt được hiệu suất tốt hơn gấp hai lần trên các lớp kết nối đầy đủ so với các GPU."
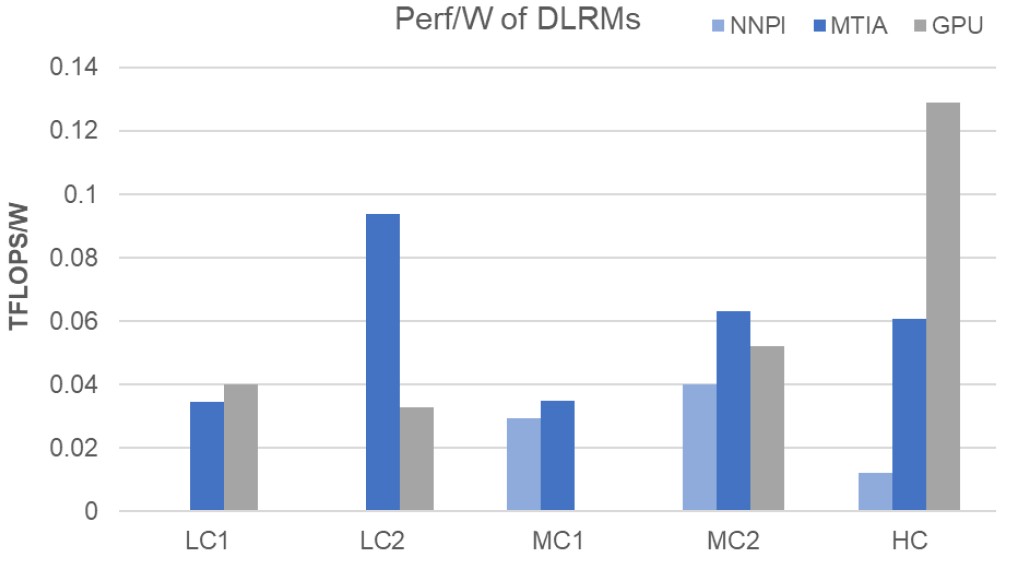
Đây là cách xếp hạng hiệu suất mỗi watt cho các mô hình phức tạp thấp, trung bình và cao:
Levenstein cảnh báo rằng thiết bị MTIA chưa tối ưu cho suy diễn DLRM trên các mô hình với độ phức tạp cao.
Chúng tôi sẽ cố gắng tìm hiểu các NNPI và GPU đã được thử nghiệm ở đây và thực hiện một chút phân tích giá hiệu suất. Chúng tôi cũng sẽ suy nghĩ xem làm thế nào để tạo ra thiết bị huấn luyện AI từ vi mạch nền tảng này. Hãy đồng hành cùng chúng tôi.
Đặc trưng của những điểm nổi bật, phân tích và câu chuyện tuần được gửi trực tiếp từ chúng tôi đến hộp thư đến của bạn mà không có bất cứ trung gian nào. Đăng ký ngay.