Microsoft Research vừa mới mã nguồn mở Visual ChatGPT, một hệ thống chatbot có khả năng tạo và điều khiển hình ảnh phản hồi với các thông điệp văn bản từ con người. Hệ thống kết hợp ChatGPT của OpenAI với 22 mô hình nền tảng hình ảnh (VFM) khác nhau để hỗ trợ tương tác đa dạng. Hệ thống đã được miêu tả trong một bài báo được xuất bản trên arXiv. Người dùng có thể tương tác với bot bằng cách gõ văn bản hoặc tải lên hình ảnh. Bot cũng có thể tạo hình ảnh, dựa trên yêu cầu văn bản hoặc bằng cách điều khiển những hình ảnh trước đó trong lịch sử trò chuyện. Module chính trong bot là Prompt Manager, sửa đổi văn bản thô từ người dùng thành thông điệp "chuỗi suy nghĩ" giúp ChatGPTxác định xem cần sử dụng công cụ VFM để thực hiện một tác vụ hình ảnh hay không. Theo nhóm Microsoft, Visual ChatGPT là:
một hệ thống mở tích hợp các VFM khác nhau và cho phép người dùng tương tác với ChatGPT vượt xa định dạng ngôn ngữ. Để xây dựng một hệ thống như vậy, chúng tôi đã chi tiết thiết kế các thông điệp để giúp tiêm thông tin hình ảnh vào ChatGPT, từ đó có thể giải quyết các câu hỏi về hình ảnh phức tạp từng bước một.
ChatGPT và các mô hình ngôn ngữ lớn khác (LLM) đã cho thấy khả năng xử lý ngôn ngữ tự nhiên đáng kể; tuy nhiên, chúng được huấn luyện để xử lý chỉ một chế độ đầu vào: văn bản. Thay vì huấn luyện một mô hình mới để xử lý đầu vào đa phương tiện, nhóm Microsoft đã thiết kế một Prompt Manager để sản xuất đầu vào văn bản cho ChatGPT với kết quả kích hoạt các VFM như CLIP hoặc Stable Diffusion để thực hiện các tác vụ thị giác máy tính.
Prompt Manager dựa trên một Agent LangChain, và các VFM được xác định là Công cụ Agent LangChain. Để xác định liệu có cần một công cụ không, agent tích hợp đầu vào từ thông điệp của người dùng và từ lịch sử trò chuyện, bao gồm tên tệp hình ảnh, sau đó áp dụng tiền tố và hậu tố thông điệp. Tiền tố bao gồm văn bản:
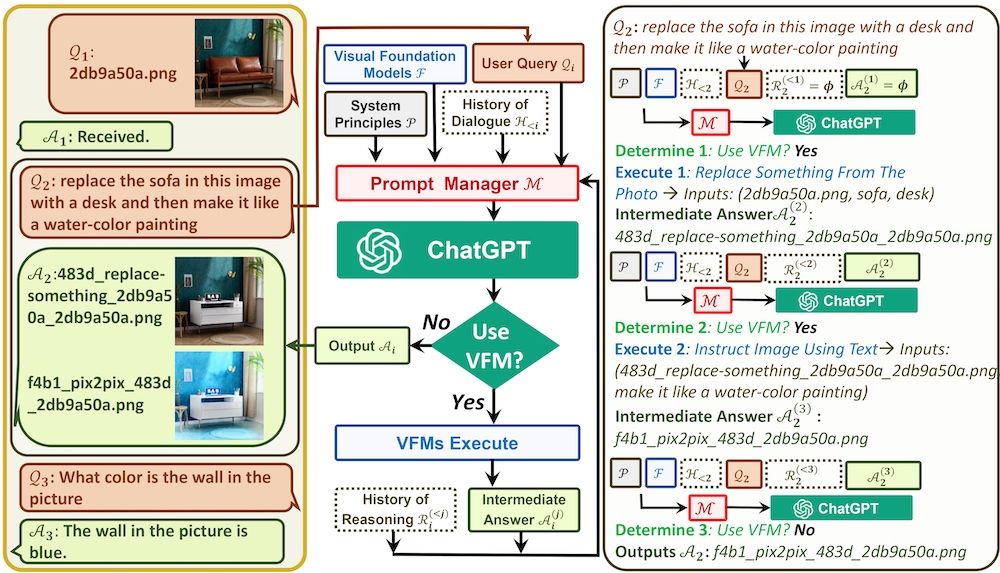
Visual ChatGPT không thể đọc trực tiếp hình ảnh, nhưng nó có một danh sách công cụ để hoàn thành các tác vụ hình ảnh khác nhau. Mỗi hình ảnh sẽ có tên tệp được hình thành thành "ảnh/xxx.png", và Visual ChatGPT có thể triệu hồi các công cụ khác nhau để hiểu hình ảnh gián tiếp.
Văn bản bổ sung trong tiền tố hướng dẫn ChatGPT hỏi chính mình "tôi có cần sử dụng công cụ không?" để xử lý tác vụ yêu cầu của người dùng, và nếu vậy, nó sẽ đưa ra tên công cụ cùng với các đầu vào yêu cầu của nó, chẳng hạn như tên tệp hình ảnh hoặc mô tả văn bản của một hình ảnh để tạo ra. Agent sẽ lặp đi lặp lại triệu hồi các công cụ VFM, gửi hình ảnh kết quả đến cuộc trò chuyện, cho đến khi nó không cần sử dụng công cụ nữa. Khi đó, đầu ra văn bản cuối cùng được gửi đến cuộc trò chuyện.
Trong một cuộc thảo luận trên Hacker News, một người dùng lưu ý rằng các VFM sử dụng ít bộ nhớ hơn các mô hình/ngôn ngữ; và người dùng khác trả lời:
Mô hình hình ảnh có thể rất không chính xác và vẫn tạo ra một kết quả đã thu hút được. Hãy nghĩ rằng tôi có thể biến đổi hầu hết các pixel trong một hình ảnh một cách ngẫu nhiên khoảng 10% và bạn sẽ chỉ nhìn thấy nó là hình ảnh chất lượng thấp một chút nhưng vẫn rất đẹp. Các mô hình ngôn ngữ không có may mắn như vậy, vấn đề họ đang cố gắng giải quyết rất "sắc bén", rất dễ để kết quả của họ bị sai nếu họ không chính xác theo một chút. Vì vậy, bạn cần một mô hình lớn hơn nhiều để đạt được mức độ "sắc bén" đủ cho văn bản."
Mã nguồn Visual ChatGPT có sẵn trên GitHub.





